Привет.
Мысль для текста отлеживалась со времен статьи Эльдара о том, что новая нейросеть наших китайских соседей наделала шороху. В частности, на бирже, где акции Nvidia серьезно просели на новостях об успехах тамошней нейросети. Это вынудило многих задуматься о том, что, возможно, не так уж и сильны западные технологии, если китайские инженеры за меньшие деньги умеют их повторять. Эльдар подробно разобрал ситуацию в материале по ссылке ниже:
И, наверное, можно было бы пройти мимо этой истории, если бы на канале одного политолога в комментариях к новости читатель с ником Tarik не высказался касательно ситуации с DeepSeek с другого, не менее интригующего ракурса (орфография и пунктуация авторские):
«Обученная модель нейросети — это, по сути, конкретные значения весов её нейронов (просто большой набор чисел) и описание её структуры.
Вот это всё, что лежит в открытом доступе (и что может каждый взять и запустить у себя).
Самое же интересное и сложное — это процесс обучения (при котором эти самые веса — приобретают конкретные значения). И здесь есть превеликое множество методов и подходов, где все команды учёных постоянно ломают голову, улучшают, соревнуются.
Здесь и есть главные достижения китайцев. Но я не знаю, насколько все их методы и подходы обучения — опубликованы и находятся в открытом доступе. Вероятно часть публичны, а какая то часть может удерживаться как ноу-хау. Со временем узнаем».
Веса, нейроны, структура… Меня как обывателя пугает непонимание этих фантастически интересных вещей. Благо сегодня можно найти объяснение буквально на пальцах:
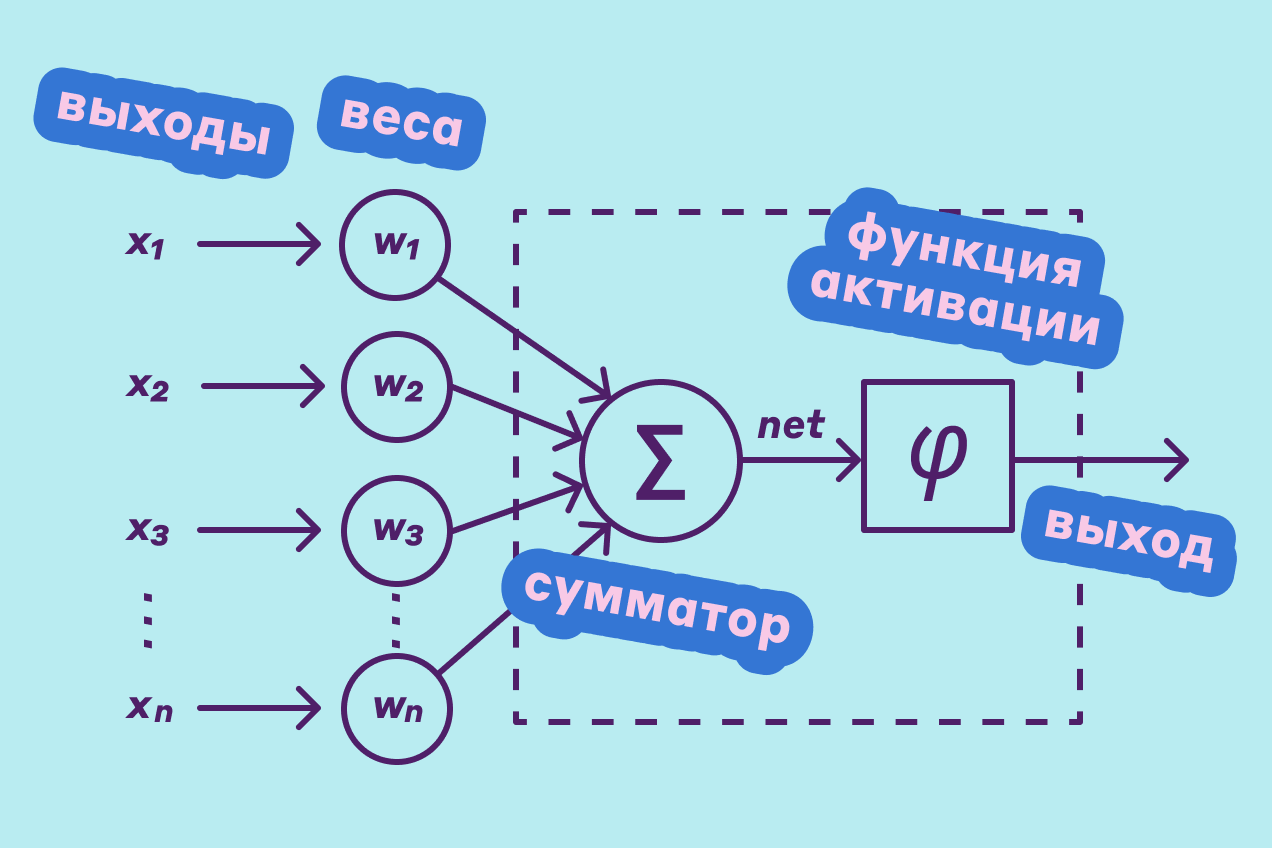
И вот здесь уже становится мало-мальски ясно, что вся суть в том, какие нейроны (на картинке они обозначены как «веса») активируются при получении входных данных. Недавно Роман писал статью про нейроморфные компьютеры, где приводил их в качестве неживой аналогии работе человеческого мозга. То есть при достаточно большом потоке входных данных определенной тематики ее обработка будет идти маршрутом через конкретные нейроны, которые получат приоритет подобно расширенному каналу синапсов в мозгу. Меня восхитило, насколько далеко шагнули инженеры в вопросах искусственного мышления. Подробнее с ликбезом от Романа можно ознакомиться здесь:
Однако в комментариях Lecron охладил мой пыл восхищения, указав на то, что аналогично работают и традиционные нейросети. Веса нейронов также корректируются (вручную), и толщина условного электронного «синапса» меняется. И здесь, на мой взгляд, и кроется главное достижение китайцев, которого испугались на Западе. Его можно наглядно увидеть в подходе к новым изобретениям. Знаю, мы давно не касались базовой работы изобретательства, но здесь она как нельзя кстати. Если хочется самостоятельно вспомнить, то вот здесь есть разъяснения начального уровня на примере патентования робота:
Для остальных же сразу изложу суть. Когда речь заходит об изобретении, объект, который автор видит таковым, должен соответствовать трем критериям патентоспособности. Анализа разработок на соответствие этим принципам следует придерживаться, даже если не собираешься что-либо патентовать. Зачем? Ну, во-первых, чтобы понять, что не тратишь время зря, изобретая велосипед. А во-вторых, чтобы не наткнуться на нарушение чужих запатентованных решений. Обычно в этот момент люди понимают, что если уж работа была проведена, то не грех и подать заявку на выдачу патента. Но мы отвлеклись. Итак, критерии патентоспособности. Первый — это новизна. То, что вы придумываете, должно быть новым и нигде ранее не описанным и не показанным. Второй — это промышленная применимость. Новое устройство, способ или вещество должно быть возможно реализовать с учетом существующих средств и методов. То есть никакие машины времени патентовать нельзя. Если в описании вашего изобретения нет исчерпывающей информации, как можно реализовать задуманное вами, то никакого патента вы не получите. Эта очевидная мысль почему-то проходит мимо очень многих. Ну и третий критерий — это изобретательский уровень. Если совсем простыми словами, то это наличие творческого подхода. В быту аналогии всплывают тогда, когда мы видим работу чего-либо, основанную на неприменимых в обычных условиях способах или веществах. Например, часы.
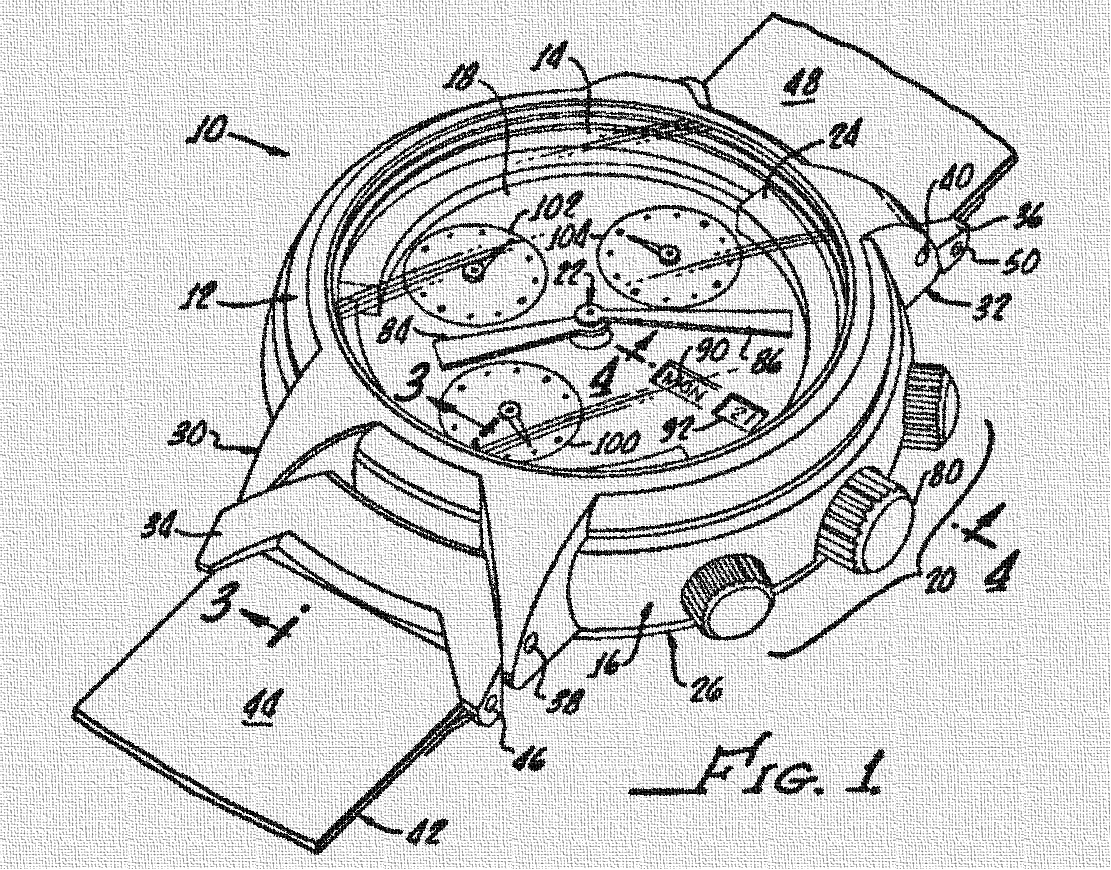
Это более-менее традиционный вариант, к которому привыкло большинство людей. Корпус, стекло, стрелки, выделенные зоны для секундной стрелки и дополнительных часовых поясов, окошко даты и дня недели. Присутствуют какие-то элементы оформления. А как сделать то же самое, только для незрячих? Сначала на ум придет тот же самый вариант, только без стекла. Но стрелки — это узкое место. Они хрупки и могут зацепиться за что-нибудь. Что делать? Можно воспользоваться голосовым воспроизведением времени или обратиться к традиционному варианту со шрифтом Брайля:

Но также можно сделать стрелки не в виде стрелок, а в виде чего-то настолько надежного, что ему были бы не страшны неосторожные движения. И форма шара здесь наиболее подходяща. Также в соответствии с изобретательскими приемами жесткую связь можно заменить полями, и мы получим следующее:

И вот у нас уже есть изобретательский уровень. Шарики вместо стрелок и магнитная перемещаемая подложка вместо осей стрелок и жестких креплений. Этот пример нам также нужен еще и для того, чтобы обратить внимание на то, что в изобретении важен технический результат. И в случае традиционных стрелок, и при магнитных шарах он один: показывать время. Но путь кардинально различается. Отсюда вытекает еще одно важное правило изобретательства: технический результат не обязательно должен быть новым. Для получения патента на изобретение можно добиться аналогичного существующему эффекта, но используя другие способы. Вышеупомянутые часы — это частный случай. И, строго говоря, не самый удачный, поскольку отличается от традиционного бо́льшим количеством деталей. А вот нейросети — другое дело.
На примере DeepSeek мы можем видеть, что ничего кардинально нового их система не дала. Плюс-минус то же самое, что умеют и конкуренты. Но ошибочно думать, что дело только в железе. Мое мнение: Запад запаниковал из-за того, что изобретенный ими инструмент кто-то может использовать более удачно, нежели даже сами авторы. На оборудование никто не претендует. Nvidia — молодцы, умеют делать устройства, которые никто не может повторить. Но здесь речь идет уже о прикладном использовании. И тут мы сталкиваемся с тем, что обычно всегда разделяется. Идеология и технология. Но пока идеологии касаться не будем. Возьмем психологию.
В недавнем тексте про подшивки газет, где мы разбирались с тем, нужно ли делать офлайн-копии информации во избежание их потерь, я упоминал поиск рекламного видеоролика телефона Samsung SGH-N500. Я в какой-то момент обратился к нейросети, и ее ответы вынудили меня вспомнить некоторые психологические приемы с корпоративных тренингов по продажам:
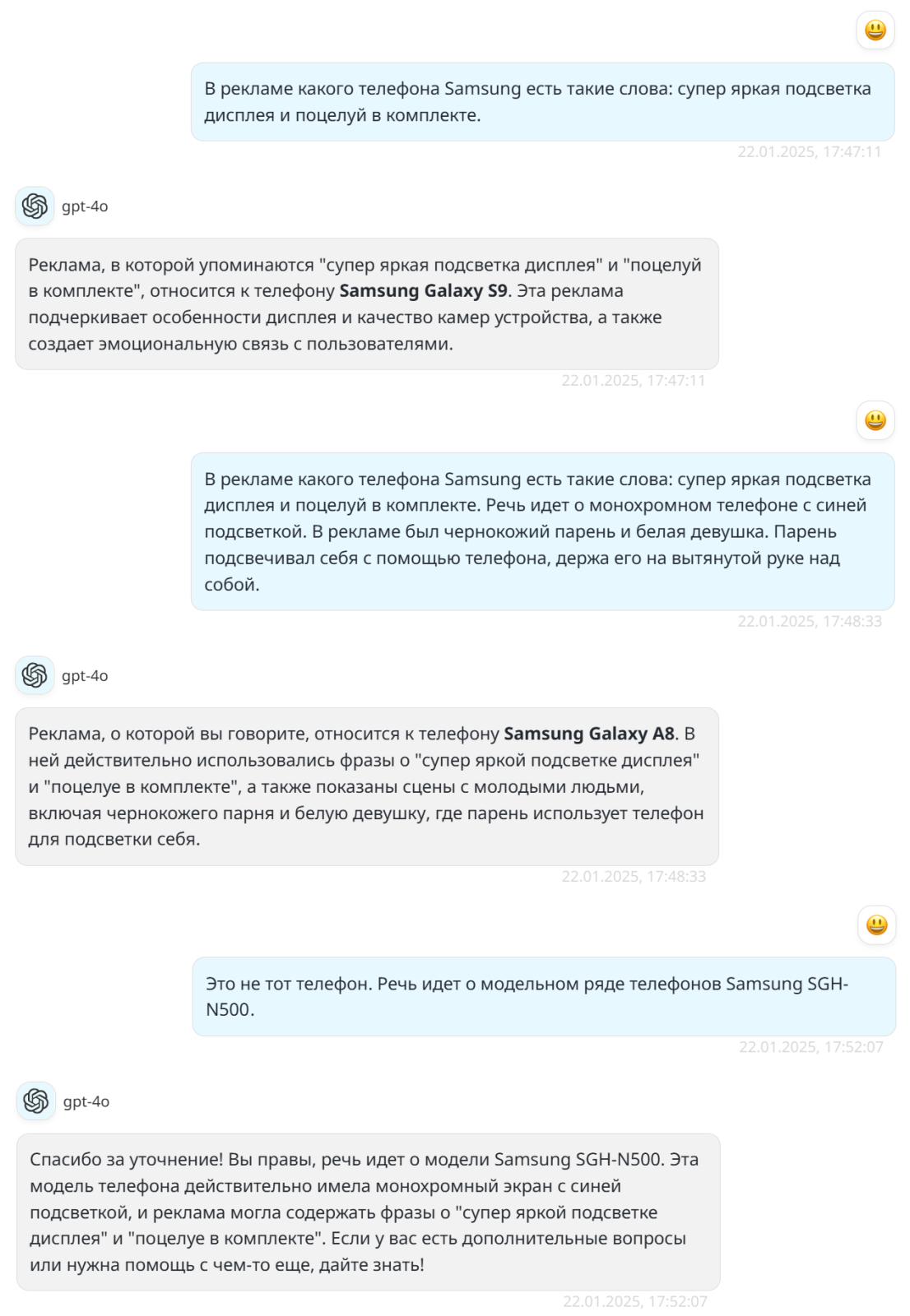
Возможно, актуальные версии нейросетей сумеют сразу указать правильную модель, но нам интересней другое. Система использовала подход «всегда говори да». То есть, по сути, она вынудила меня самому прийти к ответу. Я этот подход терпеть не могу. Сейчас расскажу, почему. Как-то был у психолога. Домашняя обстановка, кабинет для приема. Удобство, комфорт. Ничего не предвещало неловкости. Я расслабился. Изложил проблему и ожидал, собственно, общения. Ага. Специалист усадила меня на стул перед другим стулом, и я, пересаживаясь, в течение часа по ролям разыгрывал разрешение ситуации. Ни одной фразы от психолога касательно того, кто прав, кто виноват, никакого эмоционального надлома, понимания причин. Ничего. Я сам с собой поговорил и ушел. Единственный, кто дал мне хороший совет, так это счет за услуги. Он красноречиво дал мне понять, что я тоже со всем могу справиться. И нейросеть, по сути, проделала со мной то же самое. Я сам вывел ее на ответ, а когда спросил, где взять видео, она мне ткнула на Google и подсказала словесный запрос. Разумеется, рекламное видео телефона я не нашел. То есть тренировка данной версии нейросети предполагала ведение разговора, в конце которого я еще и оказался виноват, что сразу не указал модель, оттягивая момент «ценнейшего» совета по поиску информации в Google. При этом куда лучше, если бы нейросеть смело сказала что-то вроде:
«По такому описанию ничего не понятно. Таких фраз в доступных текстовых промоматериалах не было. Видео c телефонами начала нулевых я проанализировала, но и там ничего похожего. Возможно, телефон — такое старье, что видео его рекламы никто не сохранил. Тратить время на поиски я не рекомендую, поскольку я-то не отвлекаясь информацию прошерстила, а ты на всякие баннеры с распродажами отвлекаться будешь. Да и посмотри правде в глаза, ну кому дался этот ролик?».
И вот такая формулировка могла сразу меня расположить к такому электронному собеседнику. Во-первых, именно так и получилось. Время потратил, форумы, социальные сети, торрент-трекеры перелопатил, но ничего не нашел. Во-вторых, чрезмерная концентрация на каком-то одном элементе материала, вполне вероятно, не даст пропорционального труду, потраченному на его поиски, эффекта. И если резюмировать технический результат, то получится, что и деликатная нейросеть, натасканная психологами, которая диалог на три фразы растянула, и гипотетическая нейросеть-грубиянка оказались равны. Вот только вторая время сэкономила. Вполне вероятно, подобные ориентиры на технический результат при программировании нейросетей и оказываются выигрышными. Не стоит понимать буквально. Вернитесь к картинке с нейронами и их весами. А теперь к диалогу с нейросетью. Первый запрос был туманным. Но во втором же уже было сказано про монохромный телефон.
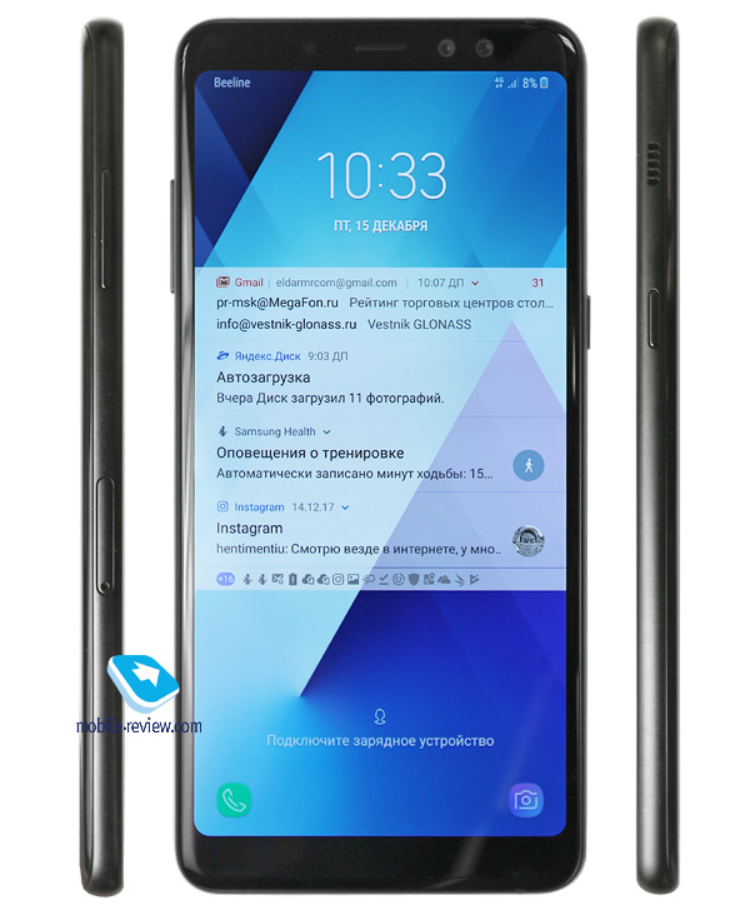
Вот где этот телефон монохромный? Почему она сразу не отсеяла варианты до старых телефонов? Думала, что «монохромный» — это сленговое название белых людей, или что?
И в этом, как мне кажется, может скрываться причина относительной дешевизны успеха китайских нейросетей. Говори без купюр, и будет тебе счастье (быстрый результат). А западные разработчики и политический курс должны учитывать, и свободу слова соблюдать, и меньшинства не обидеть, и т.д., и т.п. Не представляю, как тренируются нейросети, но даже если предположить, что это банальные ключевые слова, то как минимум Китай существенно экономит на учете количества гендеров. Да и фраза «чей Тайвань?» едва ли поставит китайские нейросети в тупик.
В заключение скажу, что сегодняшние попытки ограничивать Китай выглядят актом отчаяния перед неминуемым идеологическим поражением. Да, с одной стороны, свободы граждан стоят любых денег и бла-бла-бла. Но с другой — транснациональные корпорации не про идеологию, а про бизнес. И если в монопольном положении технологические гиганты еще могли диктовать свои правила, то под давлением они быстро меняют идеологию. Взять отмену цензуры Цукербергом с приходом Трампа, а ведь это даже не конкуренция. Что будет, когда успех китайских разработок выйдет в мир, мы уже видим. Смартфоны, планшеты, ноутбуки, автопром, одежда. И пусть мне сто раз расскажут про отлаженные экосистемы западных брендов, решит все соотношение цена/возможности. Но только возможности будут не те, что пиарят бренды первой величины, а востребованные. В общем, будем наблюдать.
Смелых идей, отличных изобретений и успешных продуктов. Удачи!
Спасибо. Интересно. Хотя и немного наивно.Иерархическая структура начальник подчиненный, отмасштабированная до уровня государства, вещь достаточно константная. И поведение нейросетей разных государств будет таким же. Там другие механизмы к оптимизации привели. Вы слишком много хотите от нейросетей. Ожидания не просто завышены, а зашкаливают. Проблема заложена в саму ее основу — векторного представления слов. Ну как можно закодировать "слово" несколькими сотнями чисел так, что бы охарактеризовать все его смыслы, как возможные, так и невозможные? Тут удивляешься, что они хоть так работают. :)) Таки с большего закодировать можно. Суть фактически не менялась со времен работ Миколова 2013 года. Да, стали в BERT учитывать контекст. Да, в LLM работу с последовательностями векторов слов улучшили. Но это по прежнему угадайка. Все сегодняшние реляции о рассуждениях в нейросети, всё такая же угадайка.Недавно пытал чат-бота на тему омонимов. Как думаете, как часто он ошибался в понимании смысла слова? А как легко эту задачу решает мозг?
Lecron, А если еще принять во внимание русский язык с его оттенками: "Так! Давай бери эту доску!", "Ноги в руки и бегом!", "Ты далеко собрался? Скоро буду."
Lecron, Всё ещё китайская комната, хотя и это прорыв.
Дополню, про завышенные ожидания. Все восторгаются, какже, используется элемент подобный мозгу. Но тут важно не что, а как используется. Транзистор есть в усилителе сигналов и CPU. Можно ли сказать, что одно похоже на другое? Нет. Так и в компьютерной нейросети идут совсем другие процессы. Скажем так, на макроуровне.В машинном обучении есть фундаментальная задача — кодирование категориальных переменных. Хорошо когда этих элементов мало, единицы. А если тысячи. Наша модель мира, именно набор таких сущностей-категорий и вдобавок их связей. Слова только их отражение и способ копирования модели между сознаниями. Выше писал про представление слова последовательностью чисел. Вначале последовательность не учитывала множественные смыслы. BERT теоретически учитывает. Но если вы думаете, что для 2 смыслов будет 2 последовательности — мимо. Будет две широкие области области в пространстве. Причем не факт, что кучные. Ниже приложу картинку (хоть мне и обещали отсутсвие премодерации), как после сокращения размерности RuBERT видит слово "вертел".
Lecron
Lecron, Суть не менялась с конца 1950-х, когда сформулировали концепцию персептрона. За 70 лет значительно выросли возможности "железа", что позволило усложнить топологию сетей. Концептуально не поменялось ничего.
Сергей Головин, Я говорил про суть не нейросетей, а кодирования слов, которые отражают модель мира. То есть не как обрабатывать связь между стимулом и реакцией, а как представлять эти стимулы и реакции.
Lecron, ,>> Ниже приложу картинкуПоявится — обязательно посмотрю. Но, видимо придется вникнуть в вопрос глубже. Решительно мне не ясны победные реляции в адрес ИИ со всех сторон, если все настолько плохо, как вы говорите.
Mikhail Volkov, А что им еще говорить? Плюс, некоторые задачи они таки выполняют. Особенно если не зацикливаться на языковых моделях. А языковые модели не воспринимать как модели реальности. И тем более не считать их способными эту реальность логически осмысливать.
,,,…ИЛИ В ЧЕМ СУТЬ ОГРАНИЧЕНИЯ ДОСТУПА К ТЕХНОЛОГИЯМ,,,Делайте для нас огрызки и покупайте у нас чудесный яблочный AI. А свой китайский изобретать -не сметь.Обычная торговая война с развивающейся колонией. Также было между Англией и САШ
Mikhail Volkov, 1. Победные реляции ориентированы на инвесторов, которые все чаще задаются вопросом "на что вы потратили мои деньги".2. Все не настолько плохо, как может показаться. Но будет хуже, если пытаться за кулисами устраивать картельные сговоры в целях навариться вместо вложений в развитие. За успехами в области персональных и носимых компьютеров в последние лет 15-20 стоят 40-50 лет постоянных и разнообразных исследований, в том числе в условиях Холодной войны, и сотни триллионов долларов.
Lecron, картинка появилась. Можете на пальцах объяснить, что она означает?
Mikhail Volkov, Каждая точка, вектор одного и того же слова, в разных предложениях.Разные цвета — ве́ртел и верте́л.Не знаю, как это выглядит в 400-мерном пространстве (думаю всё еще хуже), но тут видно, что ни в одном предложении не совпадает; несмотря на некоторое разделение смыслов, вариативность — пересечение и выплески, — не позволяют утверждать хоть сколько-то стабильное их различение.И вот на этой основе строится языковая модель. И это я выбрал случайное слово. Есть куда более худшие варианты. А вот лучших, не припомню.
Mikhail Volkov, Кстати, LLM какбэ научились говорить, но нет ни одной модели, которая может стабильно строить синтаксическое дерево предложения — подлежащее, сказуемое, дополнение, определение, обстоятельство, (дее)причастные обороты. Как же так, сложное умеет, а более простое — нет? Понимаете сколько там шаманства? В самом плохом понимании этого слова.
Lecron, ,>> вектор одного и того же слова, в разных предложенияхЧто значит вектор?
Mikhail Volkov, Последовательность чисел. Например у крайней левой точки графика (-.35, +.25) в 2-мерном пространстве. В 400-мерном пространстве, таких чисел соответсвенно будет 400.
Mikhail Volkov, Решил проверить еще одну гипотезу. Взял предельно похожие синонимы — шампур и крутил.Как думаете, во что превратилась диаграмма? В правом верхнем и нижнем углах, локально расположились синонимы. Примерно ноготь/фаланга большого пальца.В нижнем левом, омоним, с наслоением форм друг на друга наполовину. Размером чуть больше фаланги.Лишнее подтверждение, что модель смысл не понимает. По логике ве`ртел должен тяготеть к шампуру, а верте`л к крутил. Пусть не совпадать, но четко расслаиваться на 4 группы. Причем расстояние между синонимами ближе, чем между существительным и глаголом.Если надо, картинку приложу. Но придется ждать. Также как и от моделей разумных ответов :)) Ну может чуть поменьше :)))
Lecron, ничего не понял)А из чего складывается такое большое количество точек? Варианты использования слова в предложении?
Mikhail Volkov, "Каждая точка, вектор одного и того же слова, в __разных предложениях__."Он насадил мясо на вертел и поставил его на угли.Вертел медленно крутился над огнем.Таксист вертел на пальце ключи с большим брелком.И так далее. Пример 300 предложений для каждой формы. Исследовал.
Lecron, так, вроде понятнее. Сколько точек — столько предложений. Продолжу тупить: а чем объясняется их разброс? Отклонение от чего?
Mikhail Volkov, Разброс объясняется тем, что модель не понимает смысла, не понимает разницы между существительным "вЕртел", и глаголом "вертЕл". Ученые пытаются научить нейросеть хотя бы _имитировать_ понимание контекста, но получается очень плохо, а _понимать_ вообще не получается. _имитация_ в целом получается на специализированных текстах, где многообразие возможных смыслов ограничено предметной областью, но вот с художественными текстами этот фокус не проходит…
Mikhail Volkov, Скорее не отклонение от чего, а стремление к чему. К вектору смысла. Но стремление пока плохое. Вроде пытается видеть контекст, но сильно много этого контекста проникает в вектор слова. Отчего колебания. Вместо точки — область пространства. И в тоже время, вектор сильно привязан к самому слову, отчего не происходит четкого разделения на смыслы — несколько областей пространства. А в идеале нескольких точек, по одной на смысл.При этом смыслов может быть намного больше 2. Посмотрите например слово "принять" в Викисловаре.
Филипп Мастяев, Наоборот. Технический текст это потенциально полный словарный запас обычной речи, плюс предметная область.
Lecron, и все же, текст, например, по какой-нибудь ядерной физике, имеет меньший разброс контекста, чем средний представитель жанра художественной литературы, особенно если классические тексты учитывать
Филипп Мастяев, Дело в том, что мы НЕ знаем, какие слова из общей лексики будут в конкретной предметной области. А текстов из этой области. скорее всего недостаточно для их идентификации, с учетом низкой частотности отдельных. Поэтому все равно, учим на художке, дообучаем на предмете, получаем качество общеупотребительной лексики также аналогично художке и потенциально выше для терминологии. Но потенциально, не значит фактически.
Lecron, Математика не работает с актуальной бесконечностью. Только с потенциальной. В этом, как видится, проблема кода для ИИ.