По материалам AndroidAuthority

Чипсеты наших смартфонов прошли долгий путь с самых первых дней существования Android. Еще несколько лет назад подавляющему большинству бюджетных смартфонов катастрофически не хватало производительности, а нынешние устройства среднего сегмента работают практически так же хорошо, как и флагманы годичной или двухлетней давности.
И теперь, когда средний смартфон способен более чем достойно справляться с повседневными задачами, как производители чипсетов, так и разработчики ПО стали ставить перед собой более высокие цели. И такие технологии, как искусственный интеллект и машинное обучение, занимают центральное место. Но что такое машинное обучение на устройстве, особенно для конечных пользователей, таких как мы с вами?
В прошлом задачи машинного обучения требовали, чтобы данные отправлялись в облако для обработки. У этого подхода есть много недостатков, от медленного времени отклика до проблем с конфиденциальностью и ограничений пропускной способности сети. Однако современные смартфоны могут генерировать предсказания полностью офлайн благодаря достижениям в дизайне чипсетов и исследованиям в области машинного обучения.
Чтобы понять последствия этого прорыва, давайте посмотрим, насколько машинное обучение изменило то, как мы используем наши смартфоны каждый день.
Рождение машинного обучения на устройстве: улучшенная фотография и предсказание при вводе текста
В середине 2010-х годов в индустрии началась гонка за улучшением качества фотографии от года к году. Это, в свою очередь, стало ключевым стимулом для внедрения машинного обучения. Производители поняли, что эта технология может помочь сократить разрыв между смартфонами и фотоаппаратами, даже если первые будут недостаточно продвинутыми с аппаратной точки зрения.
С этой целью почти все крупные технологические компании начали повышать эффективность своих чипов при решении задач, связанных с машинным обучением. К 2017 году Qualcomm, Samsung, Apple и Huawei выпустили чипсеты или смартфоны с выделенными подсистемами для машинного обучения. За прошедшие с тех пор годы камеры смартфонов совершенствовались, особенно с точки зрения динамического диапазона, уменьшения шума и фотографирования при слабом освещении.
Совсем недавно такие производители, как Samsung и Xiaomi, нашли новые варианты использования этой технологии. Например, у первой функция Single Take («Мультикадр») использует машинное обучение для автоматического создания альбома высококачественных фотографий из одного 15-секундного видеоклипа. У Xiaomi новая технология развилась из простого распознавания объектов до возможности замены на снимке неба целиком, если вам это потребуется.
К 2017 году почти все крупные технологические компании начали повышать эффективность своих чипов при решении задач, связанных с машинным обучением.
Многие производители Android-смартфонов теперь используют машинное обучение на устройстве для автоматического распознавания лиц и объектов в галерее вашего смартфона. Это функция, которая ранее была доступна только в облачных сервисах, таких как Google Фото.
Конечно, машинное обучение на смартфонах выходит далеко за рамки применения в фотографии. Можно с уверенностью сказать, что оно используется в приложениях для работы с текстом так же давно, если не дольше.
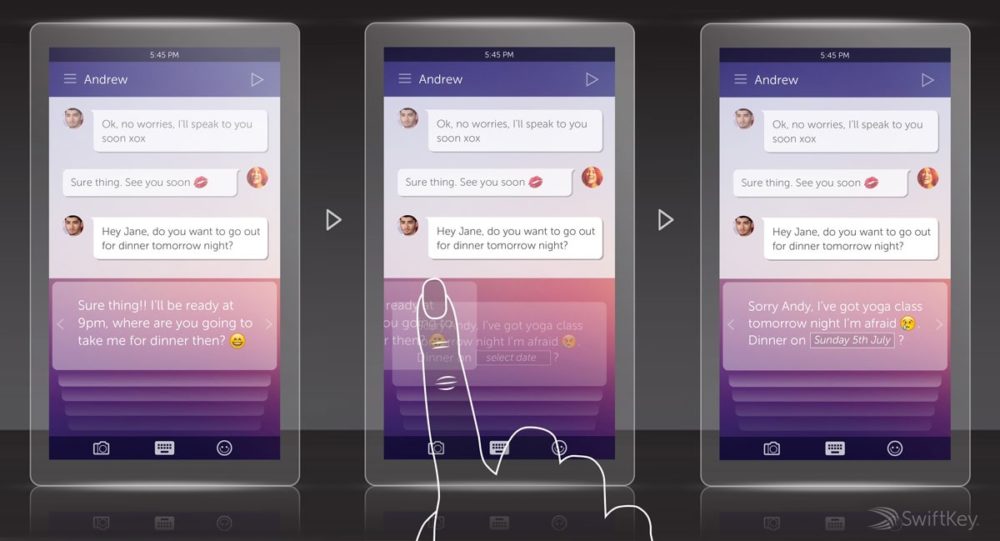
Swiftkey было, пожалуй, первым приложением, что использовало нейронную сеть для лучшего предсказания ввода текста еще в 2015 году. Компания заявила, что обучила свою модель миллионам предложений, чтобы лучше понять взаимосвязь между различными словами.
Еще одна функция появилась пару лет спустя, когда Android Wear 2.0 (теперь Wear OS) получил возможность предлагать ответы на сообщения в чате. Позже Google назвала эту функцию Smart Reply и сделала ее мейнстримом в Android 10. Вы, скорее всего, воспринимаете эту функцию как должное каждый раз, когда отвечаете на сообщение из панели уведомлений вашего телефона.
Голос и дополненная реальность: крепкие орешки
В то время как машинное обучение в области предсказания текста и фотографии уже демонстрирует зрелость технологии, распознавание голоса и дополненная реальность – две сферы, в которых каждые несколько месяцев все еще происходят значительные и впечатляющие скачки.
Возьмем, к примеру, функцию мгновенного перевода с камеры Google, которая накладывает перевод иностранного текста в режиме реального времени прямо на прямую трансляцию с камеры. Несмотря на то, что результаты не так точны, как их онлайн-эквивалент, эта функция более чем удобна для путешественников с ограниченным трафиком.
Точное отслеживание движений тела – еще одна футуристическая функция дополненной реальности, которая может быть реализована с помощью высокопроизводительного машинного обучения. Представьте себе жесты Air Motion в LG G8, только намного более продвинутые и с более широким применением, например, отслеживание тренировок и перевод с языка жестов.
Что касается речи, распознавание голоса и диктовка существуют уже более десяти лет. Однако только в 2019 году смартфоны получили возможность работать с ними полностью в автономном режиме. Чтобы быстро убедиться в этом, попробуйте приложение Google Recorder, которое использует технологию машинного обучения для автоматической расшифровки речи в реальном времени. Транскрипция сохраняется в виде текста, подлежащего редактированию, и в нем доступна функция поиска – на благо журналистам и студентам.
Эта же технология также лежит в основе Live Caption, функции Android 10 (и более поздних версий), которая автоматически создает скрытые субтитры для любого мультимедиа, воспроизводимого на вашем телефоне. Помимо пользы для людей с ограниченными возможностями, она может пригодиться, если вы пытаетесь расшифровать аудиозапись, сделанную в шумной обстановке.
Хотя это, безусловно, интересные функции сами по себе, есть также несколько путей их развития в будущем. Например, улучшенное распознавание речи может обеспечить более быстрое взаимодействие с виртуальными помощниками даже для людей с нетипичным акцентом. Хотя у Google Assistant есть возможность обрабатывать голосовые команды на устройстве, эта функция, к сожалению, эксклюзивна для линейки Pixel. Тем не менее, она дает возможность заглянуть в будущее этой технологии.
Персонализация: новая цель машинного обучения?
Подавляющее большинство сегодняшних приложений машинного обучения основаны на предварительно обученных моделях, которые заранее создаются на мощном оборудовании. Вывод решений из такой предварительно обученной модели – например, создание контекстного ответа на Android – занимает всего несколько миллисекунд.
В настоящее время разработчик обучает одну модель и распространяет ее на все устройства, где она требуется. Однако этот универсальный подход не учитывает предпочтений каждого пользователя. Он также не предполагает дополнения модели новыми данными, собранными с течением времени. В результате большинство моделей относительно закрыты и получают обновления только время от времени.
Решение этой проблемы требует переноса процесса обучения модели из облака в отдельные смартфоны – а это выглядит очень радикальным шагом, учитывая разницу в производительности между двумя платформами. Тем не менее, это позволит приложению клавиатуры, например, адаптировать свои предсказания именно к вашему стилю набора текста. Если пойти еще дальше, оно может даже принять во внимание другие контекстные подсказки, такие как ваши отношения с собеседниками.
В настоящее время Gboard от Google использует сочетание обучения на устройстве и в облаке (так называемое федеративное обучение), чтобы улучшить качество предсказаний для всех пользователей. Однако у этого гибридного подхода есть свои ограничения. Например, Gboard предсказывает следующее вероятное слово, а не целые предложения, на основе ваших индивидуальных привычек и прошлых разговоров.
Подобное индивидуальное обучение абсолютно необходимо проводить на устройстве, поскольку отправка конфиденциальных пользовательских данных (таких, например, как нажатие клавиш) в облако будет иметь катастрофические последствия для безопасности. Apple даже признала это, когда анонсировала CoreML 3 в 2019 году, что позволило разработчикам впервые переобучать существующие модели с использованием новых данных. Однако даже в этом случае большую часть модели необходимо сначала обучить на мощном оборудовании.
На Android такое итеративное обучение модели лучше всего представлено функцией адаптивной яркости. Начиная с Android Pie Google использует машинное обучение, чтобы «наблюдать за взаимодействиями пользователя с ползунком яркости экрана» и продолжать обучать модель, адаптированную к индивидуальным предпочтениям. После включения этой функции Google заявила о заметном улучшении способности Android определять нужную яркость экрана всего за неделю при нормальном взаимодействии со смартфоном. Что касается того, почему до сих пор обучение на устройстве ограничивалось лишь несколькими простыми сценариями использования, то это вполне понятно. Помимо очевидных ограничений по вычислительной мощности, емкости аккумулятора и допустимой нагрузки на системы смартфона, для этой цели разработано не так много методов или алгоритмов обучения.
И хотя ситуация не изменится в одночасье, есть причины для оптимизма в отношении машинного обучения на мобильных устройствах в ближайшее десятилетие. Поскольку технологические гиганты и разработчики ПО сосредоточены на способах улучшения пользовательского опыта и конфиденциальности, обучение на устройстве будет продолжать развиваться. Может быть, мы, наконец, сможем считать наши телефоны умными во всех смыслах этого слова.