Приветствую! На проходящий в Москве конференции AI Journey компания «Сбер» представила очередную генерацию своей нейросети Kandinsky, которая на этот раз обзавелась еще и первой для отечественного рынка функцией генерации видео. Собственно, с рассказа о том, что такое Kandinsky Video, и стоит начать.
Kandinsky Video и чем оно не анимация
С сегодняшнего дня, если вы зайдете в раздел нейросети Kandinsky на сайте «Сбера», то увидите, что Kandinsky 3.0 – это собственно ИИ для генерации картинок Kandinsky 3.0 и Kandinsky Video. Для создания роликов потребуется переход на сайт Fusion Brain или в телеграм-бот. Идея, вроде бы, та же, что и при генерации картинок: задаешь текстовый запрос и получаешь короткий ролик. Ограничения по разрешению — до 512 пикселей по наибольшей стороне и длительность до 8 секунд. Качество видео — около 30 кадров в секунду. Как видим, негусто даже по этим параметрам. Однако пока «Сбер» находится в лидирующей группе. Только появившаяся за день до полноценного релиза Kandinsky Video нейросеть Stable Video Diffusion по бенчмаркам обошла отечественный продукт, а ограничений по получаемому продукту там не меньше.
Роднит Kandinsky Video и Stable Video Diffusion и тот факт, что ни один из этих проектов не готов к тому, чтобы с его помощью создавались готовые ролики. Это скорее исследовательский проект с определенной публичной сферой демонстрации. По оценкам разработчиков в «Сбере», генерация видео по текстовому запросу выйдет на тот же уровень, не котором сейчас существует генеративный ИИ для создания изображений, примерно в течение двух ближайших лет.
Но, как говорится, это не точно. Одна из основных проблем, которые лежат перед разработчиками нейросетей для создания видео, — это отсутствие соответствующих задаче датасетов. Если Kandinsky 3.0 тренировали на 1,5 млрд пар картинка-текст, то для Kandinsky Video датасет состоял всего-то из 300 тысяч пар. И перспектив, что появятся принципиально большие, не так уж много.
Кроме того, нужно понимать, что End2End — это предсказание серии картинок, которые человеческий глаз будет потом воспринимать как видео. Для машины же это генерация некоего набора кадров, которые потом постепенно избавляются от диффузионного шума. Архитектура Kandinsky Video состоит из двух основных блоков: первый отвечает за создание ключевых кадров, из которых складывается структура сюжета видео, а второй — за генерацию интерполяционных кадров, которые позволяют достичь плавности движений в финальном видео. В основе двух блоков лежит новая модель синтеза изображений по текстовым описаниям Kandinsky 3.0. Но есть тут и проблемы. Повышение качества путем точной настройки не позволяет добиться повышения качества видео в целом. Если сосредоточиться на улучшении ключевых кадров, то качество картинки будет падать, а если пойти путем улучшения интерполяционных кадров, то начнутся проблемы понимания нейросетью собственно текстового запроса. Готового рецепта, как решить эту проблему, нет.
Собственно, так становится понятно, почему пока даже представленные «Сбером» проморолики, созданные нейросетью, не выглядят как видео уровня хотя бы не очень новой видеоигры. Однако это уже не анимация, где движение достигается за счет «пролета» камеры мимо неподвижного объекта, а движение совершают и объект в кадре, и фон, на котором он расположен. Также следует отделять видео от генерации изображений, поскольку во втором случае мы имеем дело с принципиально двухмерным объектом. Однако большинство пользователей всех этих нюансов не заметят, поскольку специалисты «Сбера» и Института искусственного интеллекта AIRI поработали и над интерфейсом Kandinsky, так что фактически с одной страницы редактора вы управляете созданием и изображений, и анимаций, и видео.
Что скрывается за переделанным интерфейсом Kandinsky 3.0
На российском рынке есть два ИИ, которые генерируют картинки по текстовому запросу, но изначально ориентировались на разный алгоритм использования. «Шедеврум» от «Яндекса» оптимизирован для того, чтобы с ним максимальный пользовательский опыт был получен с мобильного устройства, тогда как Kandinsky от «Сбера» больше ориентирован на взаимодействие с пользователями, предпочитающими настольную версию. За такой, казалось бы, мелочью, на самом деле скрывается большая идеологическая разница. «Шедеврум» больше воспринимается как забавный генератор смешных картинок, которыми удобно делиться с друзьями. Вся вот эта социальная составляющая, масштаб которой осознаешь, лишь когда задумываешься над теми механизмами, которые скрываются под ней. Десктопный генеративный ИИ настраивает на более серьезный лад, да, собственно, разработчики Kandinsky и не скрывают, что имеют конечной целью дать в руки дизайнерам новый удобный инструмент.
Кстати, важный момент. Столько слухов ходит о том, что ИИ лишит смысла одну или другую профессию, но в большинстве случаев сами разработчики говорят о том, что мы чрезвычайно далеки от того момента, когда будет получен полноценный ИИ, который сможет принимать какие-то решения самостоятельно или выдавать готовый продукт без участия человека. Если вы пользовались любой из нейросетей, которые создают изображения, то должны оценить время, которое требуется на получение мало-мальски удобоваримого изображения, которое обладало бы некоторой художественной ценностью, не имело очевидных проблем со здравым смыслом, а также соответствовало образу, который изначально требовался. Не то что получилось что-то забавное — и понесли на борду, а именно готовый продукт, сравнимый с работой художника или дизайнера, которому поставили четкую задачу.
Что же касается доступности Kandinsky, то им можно пользоваться в трех вариантах: на сайте Fusion Brain и в ботах в «Телеграме» и VK. Последние два удобны, если заходить с телефона, но в целом несколько проигрывают по удобству десктопной версии. В то же время десктопная версия на мобильных устройствах работает не очень хорошо. Обрабатывает запросы медленно, имеет проблемы с масштабированием интерфейса и т.п. Также, если вам по какой-то причине не нравится новая версия 3.0, в боте можно выбрать старую модель. Функционал в любом случае задается командами, а время генерации результата на мобильном устройстве будет меньшим в боте. Те, кому текстовый вариант с задачей параметров командами боту не нравится, могут обратиться к голосовому помощнику «Сбер Салют», будет все то же самое, но задавать требования можно голосом.
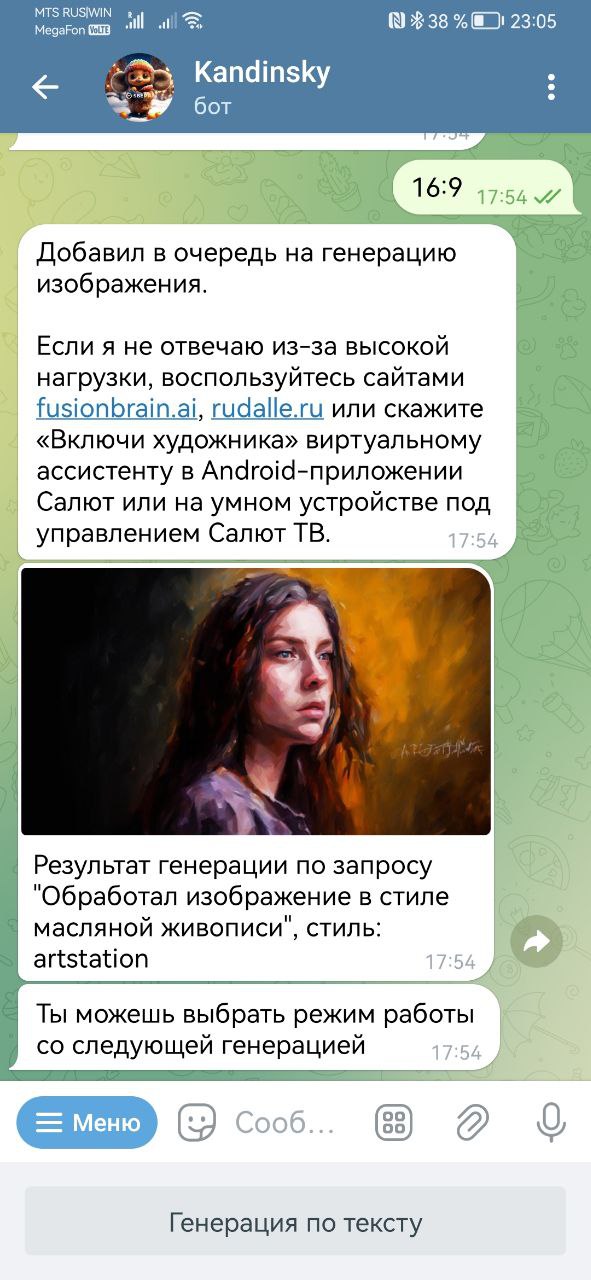
Вообще, что касается времени генерации результата, то именно Kandinsky 3.0 должен стать одним из самых быстрых генеративных ИИ. Собственно, при разработке версии одной из задач разработчиков было добиться сокращения времени, требующегося нейросети для выдачи результата. Причина банальна. Как я отметил выше, чтобы добиться результата, сравнимого с работой профессионала, придется попотеть, добиваясь от ИИ изображения нужных вещей на нужных местах. Большинство пользователей таким образом не поступают. Вместо того, чтобы доводить уже имеющееся начальное изображение до соответствия своему запросу, типичный пользователь просто создает новый запрос. Соответственно, результат достигается путем многократного повторения некоторых вариаций запроса или перехода к новому. В таком случае получается, что критичным параметром для наилучшего пользовательского опыта становится скорость, с которой нейросеть выдаст результат. И именно по этому параметру версия 3.0 будет быстрее версии 2.2, поскольку даже сама генерация изображений была сокращена на один шаг.




Предполагается, что точность при этом не пострадала, поскольку тренировали Kandinsky 3.0 на большем датасете, настраивали по 11,9 млрд параметров и использовали в 1,5 раза больший U-net. Заявляется, что Kandinsky 3.0 в 3 раза больше, чем версия 2.2, так что качество изображения будет выше. В пресс-релизах это превратилось в рассказы о более точных настройках под реалии российских запросов, понимание отечественной культуры и узнавание отечественных знаменитостей. Насколько удалось — посмотрим, времени, чтобы поработать с новой версией нейросети, было не так уж много. Хотя некоторые официальные результаты ее работы могли наблюдать пользователи приложений «Сбербанка». И я в том числе. Вот так «Сбер» поздравил с Днем народного единства:

Прямо скажем, что русский народный дух передан довольно интересным образом. Во всяком случае, мне кажется, что нейросети явно показывали вторую серию первого сезона мультсериала Metalocalypse. Но надо бы знать запрос и сколько сил потратили на то, чтобы довести изображение до конечного результата. Любопытно, что в «Сбере» еще и решили идти экcтенсивным путем привлечения аудитории, так что пользователи приложения «Сбербанка» получают возможность сами себе генерировать заставки. Идея интересная, но практически я слабо представляю, кто этим будет заниматься на постоянной основе.
Более важным, чем возможность уверенно отличать Илью Муромца от Алеши Поповича, а хохлому от городецкой росписи, мне кажется то, что доработали такую вещь, как негативный промпт. Теперь удобно стало исключать то, что вы не хотите видеть в получаемом результате. Это позволит, отталкиваясь от того, что вы где-то видели, но вам не совсем понравилось, получать то, что безусловно понравится. Вообще, работа с изображениями как с частью поискового запроса — это очевидное направление развития для всех разработчиков ИИ. «Сбер» в данном случае не уникален, но хорошо, что на это обращают внимание.
Как и на то, что одна из важных для пользователей задач — встраивание картинки в картинку. Inpainting и outpainting был прокачан, так что посмотрим, что получилось. Приводимые на презентации примеры демонстрируют, что должно быть хорошо. Но так хорошо, как у них, у меня пока не вышло, чему виной будем считать слишком ограниченное время на освоение.
В отдельную категорию создания контента выделили анимацию. Разумеется, когда мы говорим о генеративном ИИ, разделение на видео, анимацию и картинки довольно условное. В «Сбере» выбрали такой подход. Картинка — это двухмерное статичное изображение. Анимация — это deform, набор картинок, который создается нейросетью как отдельная картинка, а на выходе статичное изображение с движением камеры относительно центрального объемного объекта с наложенными эффектами. О видео поговорили выше. Анимация создается быстрее, чем видео (заявлено, что в среднем 20 секунд на 1 секунду ролика), разрешение в ней больше, но ролик ограничен 4 секундами.
Промежуточный итог
Подводить какие-то итоги под очередным шагом в развитии генеративного ИИ просто по той причине, что была презентована новая версия конкретной нейросети, не стоит. Даже для самой нейросети это всего лишь часть процесса, который все еще находится в очень ранней стадии развития. Для понимания, первая нейросеть, способная преобразовать текстовый запрос в изображение, появилась в 2016 году. Почти пять лет шел поиск модели, которая была бы сравнительно проста в обучении, но при этом давала бы результат в виде изображений высокой четкости. Для российских срок еще меньше. «Сбер» и AIRI начали работать над генеративным ИИ в 2021 году. В этом отношении Kandinsky 3.0 добилась большого прогресса за короткий срок, но во многом продолжает оставаться эдаким глобальным бета-тестом. И это я говорю только про генерацию изображений.
Что касается анимации и видео, то я бы не назвал это даже публичной альфа-версией. Это демонстратор технологий. 3-4 минуты для того, чтобы получить видеоролик, в котором происходит что-то в разрешении, достойном экрана кнопочного телефона? Нет, у этого нет никакого практического применения. Но да, это очень круто. И да, я не мог не попросить Kandinsky Video изобразить прибытие поезда. Пожалуйста, не убегайте от экрана при просмотре!