Привет.
Нам талдычат, что нейросети уже научились творить, но это всегда художественное преувеличение. «Сбер» выпустил новую версию «Кандинского», до этого нас разогревали картинками, которые, возможно, не поражали воображения, но выглядели очень любопытными. Одно дело — смотреть результаты чужих экспериментов, совсем другое — попробовать все своими руками и вынести суждение. Ниже — результаты эксперимента в официальном боте «Кандинского» для модели версии 3.1.
Начнем с простого запроса: «Красивая кошечка сидит на заборе свесив ноги». Стиль — цифровая живопись.
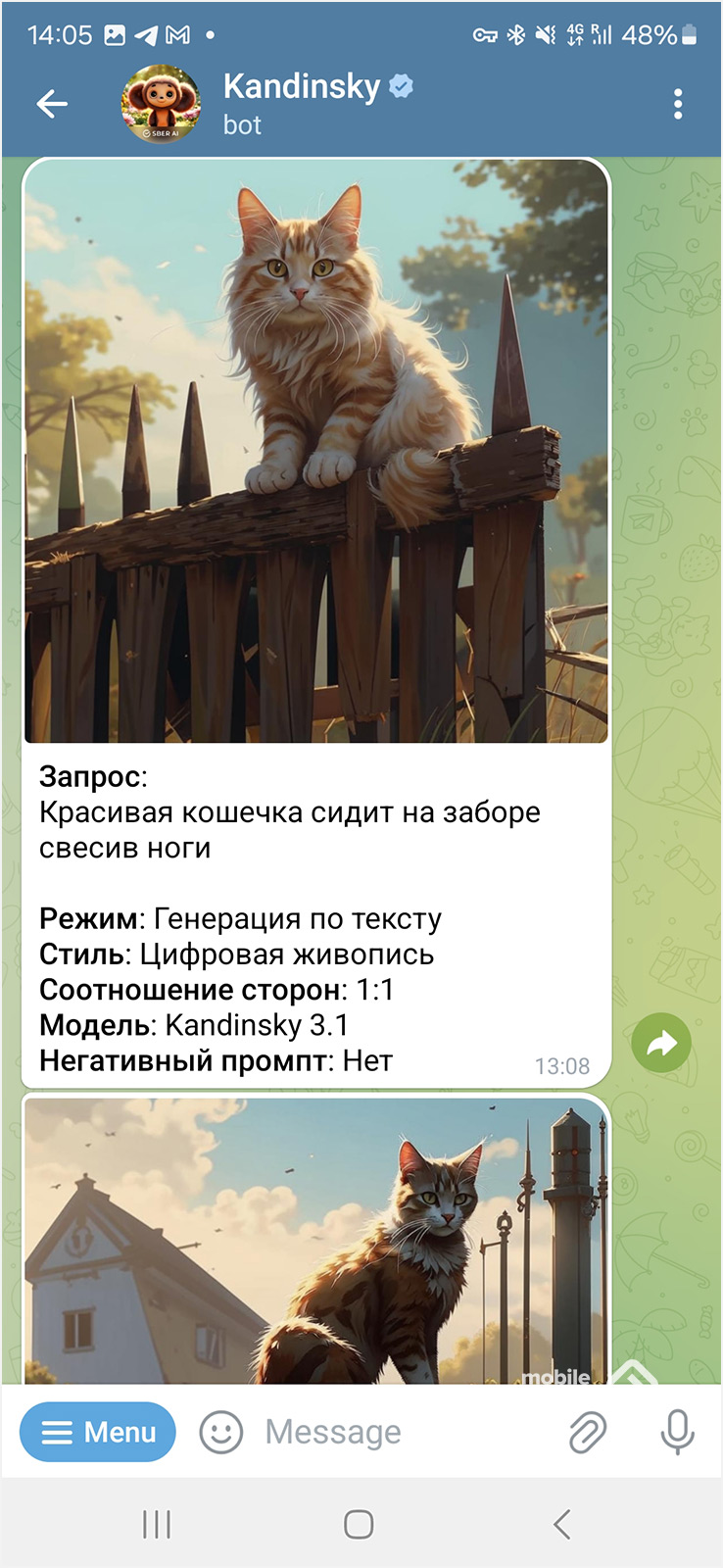
И вот что получилось.






Лишние хвосты, странные лапы. Все это присутствует в полном объеме, назвать картинку качественной можно только в одном случае — если вы не приглядываетесь к ней.
Запрос «Пианист в кокошнике играет на белом рояле мурку».

А вот что получилось.




С руками полная беда, то они длинные, то их много. Пианист — только один раз мужчина. В целом, с задачей нейросеть справилась весьма посредственно. Но это и не то, что обычно спрашивают, таких картинок в реальной жизни нет, это скорее попытка вообразить что-то несуразное. Какой вопрос, такой и ответ.
Давайте попросим нечто, что может быть реальным: «смартфон Nokia с шестью камерами цвета фуксии».

И вот что получилось в итоге.




Модель работает плохо, так как ищет примеры смартфонов Nokia, но не умеет дорисовывать к ним нужное число камер, да и с цветом корпуса выходит промашка. Использовать такие картинки где-либо невозможно.
Попробуем поработать с текстом: «Красивая надпись «Будущее не за горами», неоновый шрифт».

И вот результаты.




Начнем с того, что нейросеть не умеет рисовать на русском языке, она даже переводит надпись на английский (продукт точно российский?). Но и восстановить надпись нельзя, понять, что написано, никак невозможно.
С пониманием и трактовкой смысла у нейросети большие проблемы, она не распознает контекст и тут можно изгаляться как угодно. Смотрим на запрос: «Девушка как овца».

Вот что вышло.




Пара картинок плюс-минус совпадают с запрошенным, а вот третья изображает девушку и овцу. Произошло смешение понятий.
Попробуем запрос «Девушка змея».



Результат получился, мягко говоря, странным. Хотя аллюзия на женщину-змею тут очевидна, поиск нейросети осознать этого не может, он просто не умеет этого делать.
Пробуем другой запрос: «Дети играют в футбол на пляже, солнце светит в левом углу, на воде видны барашки, девушка в ситцевом платье стоит справа».




Барашки в данном контексте — это не животные, но в итоге мы получаем их. Солнце светит в разных углах, тут нет правильного расположения. И тут мимо.
Упростим задачу, попробуем массовую культуру: «Барби обнимает собаку на причале, вдаль уходит корабль».





Композиция пару раз угадана, но всегда есть огрехи, один снимок с натяжкой получился хорошим. И это действительно пример, когда нейросеть с задачей худо-бедно справилась.
Вернемся к игре, когда мы пытаемся придумать что-то необычное: «Батька в космосе чинит картофелину». Думаю, что всем живым людям понятен контекст.





Никакой починки в космосе не происходит, глагол для нейросети неизвестен, также как и такой предмет, как картофелина (нужно писать «картошка», и тогда все будет иначе).
Запрос «Взрыв на макаронной фабрике».
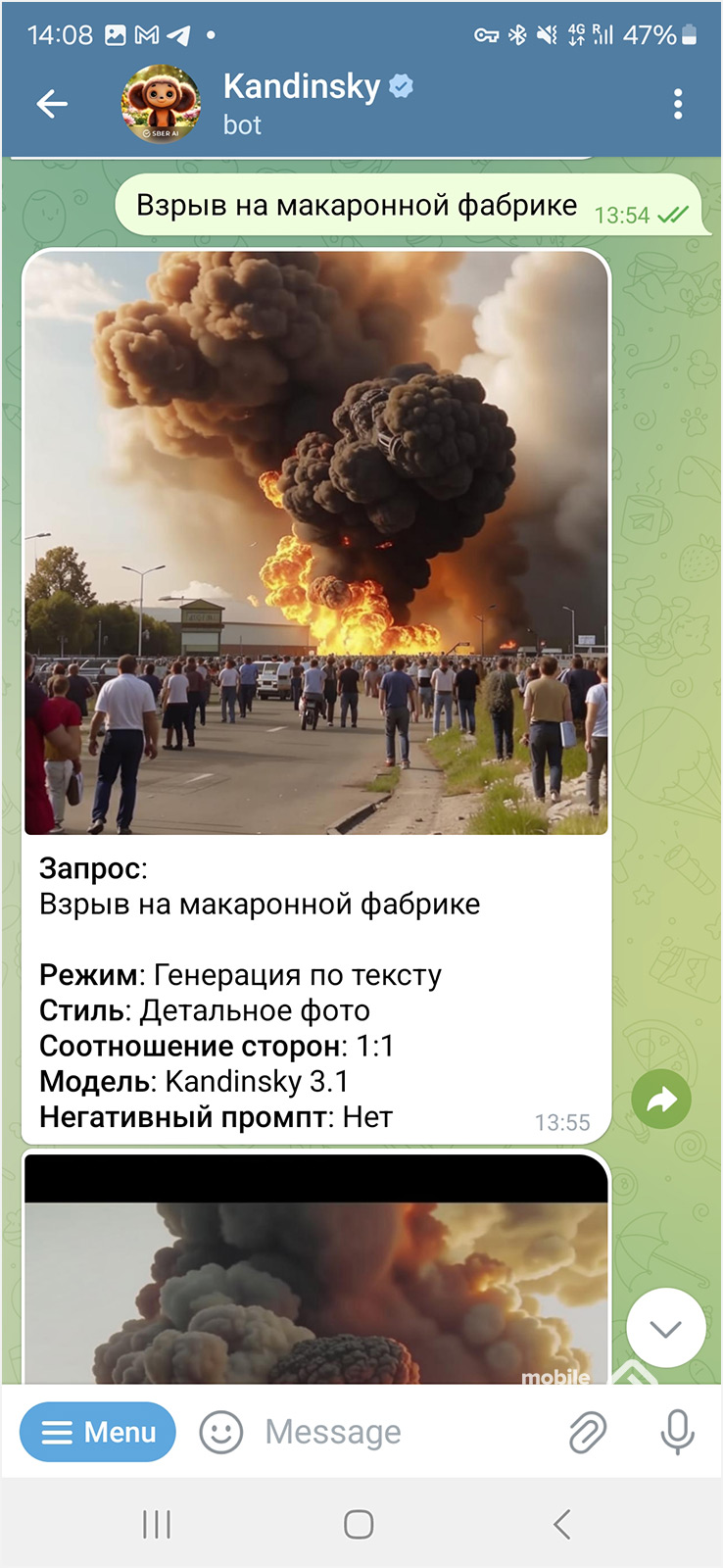




Трактовка буквальная, хотя мы понимаем, что обычно эта фраза употребляется совсем в ином контексте. Есть и запретные фразы, когда нейросеть ограничивает выдачу результата.
Попробуем переформулировать запрос: «Жизнерадостный человек с улыбкой на лице».





Ухххх, тут просто раздолье для веселья. Попробуем что-то сюрреалистическое: «Спортсмен с шестом прыгает через носорога».





Тоже получается как-то удивительно, образы для нейросети незнакомы, результат выглядит сомнительным.
Обратил внимание, что модель при генерации людей, как правило, придерживается одного выбранного лица, не меняет его, а изменяет детали картинки. Нашел ориентировку на человека и просто вбил ее в поле для создания картинки.




Полученный результат выглядит странным, но не самым плохим из возможных. Зато нейросеть отлично подходит для коллективной игры в ассоциации, называете слово, затем следующий человек — еще одно слово, и затем вы рисуете картинку. Вот так от одуванчика мы дошли до пива.





Наконец можно использовать запросы, которые приходят на ум, и смотреть, что происходит.










К сожалению, «Кандинский» не умеет рисовать по текстовым запросам так, чтобы получалось хорошо, на данный момент это игрушка и ничего более. Впрочем, как и большинство других подобных продуктов в их бесплатной версии. Считать, что такой продукт заменит иллюстратора или художника, нельзя. И это не считая юридических вопросов, а просто говоря о качестве получаемых изображений. Мне сложно предвидеть, как долго нужно эволюционировать таким системам, чтобы стать как минимум удобоваримыми. Но речь явно идет не про один-два года, а про отрезок в пять-десять лет.