Примечание редакции Mobile-review.com. Мы подбираем материалы в раздел «Мнение», чтобы показать то как воспринимают рынок, компании в других странах. Мнения в таких материалах зачастую не совпадает с взглядами нашей редакции, но дают понимание рынка, его медийной составляющей.
По материалам androidauthority.com
Более восьми лет назад мы впервые заговорили о нейронных процессорах (NPU) в наших смартфонах и о первых возможностях искусственного интеллекта непосредственно на устройстве. Не будем забывать, что первым был процессор Kirin 970 в HUAWEI Mate 10, хотя подобные идеи возникали и раньше, особенно в области обработки изображений.
Конечно, за последние восемь лет многое изменилось. Apple наконец-то взялась за работу с ИИ, хотя результаты на данный момент весьма противоречивые, а Google активно использует свой тензорный процессор везде, от обработки изображений до перевода на устройстве. В любой из крупных технологических компаний, от Arm и Qualcomm до Apple и Samsung, вам скажут, что ИИ — это аппаратное и программное будущее смартфонов.
И все же применение мобильного ИИ по-прежнему кажется довольно узким. Нам доступен ограниченный, хоть и растущий набор встроенных ИИ-функций, в основном определяемых Google, и практически не существует творческой среды для разработчиков. Отчасти в этом виноваты нейронные процессоры — не потому, что они неэффективны, а потому, что их никогда не представляли как реальную платформу. Это наводит на вопрос: для чего же на самом деле нужны эти чипы в наших телефонах?
Что такое нейропроцессор?

Прежде чем дать однозначный ответ на вопрос, действительно ли телефонам «нужен» нейронный процессор (NPU), давайте обозначим его функции.
Также как и универсальный центральный процессор в вашем смартфоне, служащий для запуска приложений, графический процессор для рендеринга игр или процессор обработки изображений и видео, NPU — это специализированный процессор, предназначенный для максимально быстрого и эффективного выполнения задач искусственного интеллекта. Всё довольно просто.
В частности, NPU разработан для эффективной работы с малыми разрядностями данных (например, 4-битными и даже 2-битными моделями), специфическими паттернами доступа к памяти и высокопараллельными математическими операциями, такими как слитные операции умножения-сложения и умножения с накоплением.
Для выполнения задач машинного обучения NPU не является строго необходимым: множество небольших алгоритмов могут довольствоваться для работы даже не самым мощным центральным процессором. А вот дата-центры, обеспечивающие работу различных больших языковых моделей, используют оборудование, которое ближе к видеокарте NVIDIA, чем к NPU в вашем телефоне.
Однако выделенный нейронный процессор (NPU) может помочь вам запускать модели, с которыми ваш центральный или графический процессор не справляется, и зачастую он может выполнять задачи более эффективно. Такой гетерогенный подход к вычислениям, несмотря на усложнение схемотехники и рост площади чипсета, компенсируется высокой энергоэффективностью и производительностью – очевидно, это ключевой фактор для смартфонов. Никому не надо, чтобы инструменты искусственного интеллекта расходовали заряд батареи смартфона.
Стоп, но разве ИИ не работает на видеокартах?

Если вы курсе кризиса цен на оперативную память, вы знаете, что дефицит обусловлен потребностями дата-центров для ИИ и спросом на мощные ускорители ИИ и графики, особенно решения от NVIDIA.
Причина высокой эффективности архитектуры CUDA от NVIDIA при работе с ИИ-нагрузками (а также графикой), заключается в ее параллельной природе. В частности, используются тензорные ядра, которые обрабатывают высокоинтегрированные операции умножения с накоплением над широким спектром матричных представлений и форматов данных, включая сверхмалые разрядности, применяемые в современных квантизованных моделях.
Современные мобильные графические процессоры, такие как Mali от Arm и линейка Adreno от Qualcomm, могут поддерживать 16-битные и всё чаще – 8-битные типы данных с высокой степенью параллелизма. Однако они не способны выполнять очень компактные, предельно квантованные модели — такие как INT4 и более низкие разрядности — с сопоставимой эффективностью. Аналогично, несмотря на формальную поддержку этих форматов на бумаге и значительный уровень параллелизма, они не оптимизированы под ИИ как основную рабочую нагрузку.
В отличие от мощных настольных графических чипов, архитектуры мобильных GPU в первую очередь проектируются с упором на энергоэффективность. Для этого используются такие подходы, как тайловые конвейеры рендеринга и сегментированные исполнительные блоки, которые не всегда хорошо подходят для длительных, ресурсоемких вычислительных нагрузок. Мобильные GPU, безусловно, способны выполнять ИИ-вычисления и в ряде сценариев показывают хорошие результаты, однако для узкоспециализированных операций часто существуют более энергоэффективные альтернативы.
Разработка программного обеспечения — вторая, не менее важная часть уравнения. Платформа NVIDIA CUDA предоставляет разработчикам доступ к ключевым архитектурным особенностям, что позволяет выполнять глубокую оптимизацию на уровне вычислительных ядер при запуске ИИ-нагрузок. Мобильные платформы не предлагают сопоставимого низкоуровневого доступа для разработчиков и производителей устройств, полагаясь вместо этого на более высокоуровневые и зачастую специфичные для вендора готовые программные пакеты, такие как Qualcomm Neural Processing SDK или Arm Compute Library.
Здесь кроется одна из ключевых болевых точек экосистемы мобильной разработки ИИ. В то время как настольная разработка в основном была сосредоточена вокруг CUDA (хотя платформа AMD ROCm постепенно набирает популярность), смартфоны используют множество различных архитектур NPU. Существуют проприетарный Google Tensor, Snapdragon Hexagon, Apple Neural Engine и другие решения — каждое со своими возможностями и собственными платформами разработки.
NPU не решили проблему платформы
Чипсеты для смартфонов, где заявлена поддержка NPU (а сегодня это практически все решения), изначально создавались для решения одной задачи — эффективной обработки малых разрядностей данных, сложной математики и нетривиальных паттернов доступа к памяти без необходимости кардинально перерабатывать архитектуру GPU. Однако выделенные NPU породили новые проблемы, особенно в контексте сторонней разработки.
Хотя для чипов Apple, Snapdragon и MediaTek существуют API и SDK, разработчикам традиционно приходилось отдельно разрабатывать и оптимизировать свои приложения под каждую платформу. Даже Google до сих пор не предоставляет простого и универсального доступа для разработчиков к ИИ-возможностям своих флагманов Pixel: Tensor ML SDK по-прежнему находится в экспериментальном статусе без гарантий полноценного релиза. Разработчики могут экспериментировать с более высокоуровневыми возможностями Gemini Nano через Google ML Kit, но это далеко от настоящего низкоуровневого доступа к аппаратному обеспечению.
Ситуацию усугубляет то, что Samsung полностью отказалась от поддержки своего Neural SDK, а более универсальный Android NNAPI от Google впоследствии был объявлен устаревшим. В результате сформировался целый лабиринт спецификаций и заброшенных API, что делает эффективную стороннюю разработку мобильного ИИ крайне затруднительной. Специфичные оптимизации со стороны вендора изначально не могли масштабироваться, так что в итоге мы получили облачные и закрытые компактные модели под контролем ограниченного числа крупных игроков, таких как Google.
К счастью, в 2024 году Google представила LiteRT — фактически перезапустив TensorFlow Lite — как единый runtime на устройстве, поддерживающий CPU, GPU и вендорские NPU (на данный момент Qualcomm и MediaTek). LiteRT был специально разработан для максимального использования аппаратного ускорения во время выполнения, оставляя программному слою выбор наиболее подходящего метода исполнения и тем самым устраняя главный недостаток NNAPI.
NNAPI задумывался как «мостик» между высокоуровневыми библиотеками машинного обучения и аппаратными ускорителями устройства конкретного вендора, но на практике он стандартизировал лишь интерфейс, а не поведение. Производительность и надежность отдавались на откуп драйверам производителей. LiteRT пытается закрыть этот разрыв, беря управление рантаймом на себя.
Примечательно, что LiteRT изначально спроектирован для выполнения инференса полностью на устройстве и поддерживает Android, iOS, встраиваемые системы и даже настольные среды. Это сигнализирует о стремлении Google сделать его по-настоящему кроссплатформенным рантаймом для компактных моделей. При этом, в отличие от настольных AI-фреймворков или diffusion-пайплайнов с десятками параметров тонкой настройки, модель TensorFlow Lite представляет собой полностью специфицированную модель: точность, квантизация и ограничения исполнения задаются заранее, чтобы обеспечить предсказуемую работу на ограниченном в возможностях мобильном «железе».
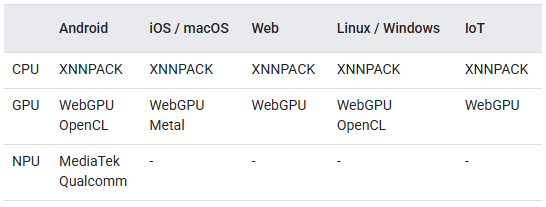
Хотя решение проблемы несовместимости NPU от разных производителей является главным преимуществом LiteRT, все же стоит задуматься, останутся ли NPU столь же значимыми, как раньше, в свете других современных разработок.
Например, новое внешнее расширение Arm SME2 для процессоров серии C1 обеспечивает до 4× ускорение для ИИ-нагрузок на стороне CPU для ряда сценариев при широкой поддержке фреймворков и без необходимости использования специализированных SDK. Также нельзя исключать, что архитектура мобильных GPU эволюционирует в сторону лучшей поддержки машинного обучения, потенциально снижая потребность в выделенных NPU.
Сообщается, что Samsung разрабатывает собственную GPU-архитектуру, ориентированную именно на ИИ на устройстве, которая может дебютировать уже в линейке Galaxy S28. В свою очередь, серия E от Imagination Technologies изначально разрабатывается как ИИ-ускоритель с поддержкой FP8 и INT8. Не исключено, что в будущем такие решения появятся и в устройствах Pixel.
LiteRT органично дополняет эти изменения, позволяя разработчикам меньше беспокоиться о том, как будет развиваться железо. Расширенная поддержка сложных инструкций на CPU делает их все более эффективным инструментом для выполнения задач машинного обучения, а не просто запасным вариантом. Параллельно GPU с улучшенной поддержкой квантизации со временем могут стать основными ускорителями вместо NPU — и LiteRT способен помочь осуществить такой переход. В этом смысле LiteRT выглядит как недостающий мобильный аналог CUDA — не потому, что он дает непосредственный доступ к аппаратной платформе, а потому, что наконец-то позволяет от нее абстрагироваться корректным образом.
Выделенные мобильные NPU вряд ли исчезнут в ближайшее время, однако жестко привязанный к вендорам подход, в центре которого стоит NPU, определявший первую волну ИИ на устройстве, очевидно, не является финальной точкой. Для большинства сторонних приложений CPU и GPU продолжат брать на себя значительную часть практической нагрузки, особенно по мере роста эффективности поддержки ими современных операций машинного обучения. Программный слой куда важнее любого отдельного кусочка кремния – он решает, как и будет ли вообще использоваться то или иное аппаратное ускорение.
Если LiteRT окажется успешным, NPU превратятся из «привратников» в обычные ускорители, а мобильный ИИ на устройстве наконец станет тем, на что разработчики смогут ориентироваться без необходимости делать ставку на дорожную карту конкретного производителя чипов. До появления по-настоящему богатой экосистемы сторонних ИИ-функций на устройствах еще предстоит пройти определенный путь — но мы наконец начинаем понемногу к этому приближаться.